
Jukebox AIとは
Jukebox AIは、OpenAIによって開発された音楽生成AIで、音楽の作曲、演奏、歌唱などを自動的に行うことができます。
Jukebox AIは、音楽のスタイル、長さ、歌詞、アレンジなど、多くの要素をカスタマイズすることができます。Jukebox AIは、音楽のプロダクションに革命をもたらすと考えられています。
Jukebox AIを始める3ステップ
ステップ1: Google Colaboratory の容量を拡張
ステップ2: Google Drive にフォルダ作成
ステップ3: コマンド実行
1ステップずつ詳細をみていきましょう!
ステップ1: Google Colaboratory の容量を拡張
Google Colaboratoryとは、Googleが提供する、Pythonの言語を記述~実行できるサービスです。
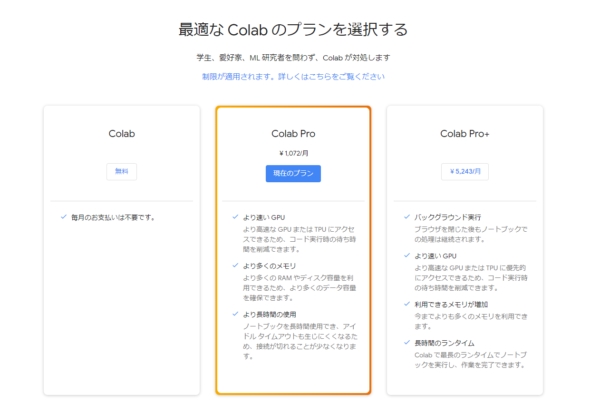
Jukebox AIを利用するには多くの容量を必要とするため、有料プランであるGoogle Colaboratory Proに契約する必要があります。(月額:1072円+税)
有料なので、まずは1か月だけJukebox AIを使ってみてハマらなかった場合はすぐに解約してみるのがよいとおもいます。

ステップ2: Google Drive にフォルダ作成
Google Driveのマイドライブ上で右クリック > 新しいフォルダ > 名前「jukebox」
※ステップ3で例として「jukebox」というフォルダを使用しているため、今回は名前を指定しています。
通常はお好きな名前のフォルダを利用できます!
ステップ3: コマンド実行
コマンドは、ステップ1の「Google Colaboratory」に記述し実行していきます!
画面上部にある「+コード」を押すことで、コマンドを記述できます。
!nvidia-smi -Lコードを入力したら、左にある実行ボタン▶を押してください。

※この後は各コードごとに実行してください。
from google.colab import drive
drive.mount('/content/drive')
!mkdir -p '/content/drive/My Drive/jukebox/'
%cd '/content/drive/My Drive/jukebox/'!pip install git+https://github.com/openai/jukebox.gitimport jukebox
import torch as t
import librosa
import os
from IPython.display import Audio
from jukebox.make_models import make_vqvae, make_prior, MODELS, make_model
from jukebox.hparams import Hyperparams, setup_hparams
from jukebox.sample import sample_single_window, _sample, sample_partial_window, upsample, load_prompts
from jukebox.utils.dist_utils import setup_dist_from_mpi
from jukebox.utils.torch_utils import empty_cache
rank, local_rank, device = setup_dist_from_mpi()model = '5b_lyrics' # '5b_lyrics' or '5b' or '1b_lyrics'で選んでください
hps = Hyperparams()
hps.sr = 44100
hps.n_samples = 3 if model in ('5b', '5b_lyrics') else 8
hps.name = '/content/drive/My Drive/jukebox' # ニューラルネットワークの出力先
chunk_size = 16 if model in ('5b', '5b_lyrics') else 32
max_batch_size = 3 if model in ('5b', '5b_lyrics') else 16
hps.levels = 3
hps.hop_fraction = [.5,.5,.125]
vqvae, *priors = MODELS[model]
vqvae = make_vqvae(setup_hparams(vqvae, dict(sample_length = 1048576)), device)
top_prior = make_prior(setup_hparams(priors[-1], dict()), vqvae, device)mode = 'ancestral'
codes_file=None
audio_file=None
prompt_length_in_seconds=Nonesample_hps = Hyperparams(dict(mode=mode, codes_file=codes_file, audio_file=audio_file, prompt_length_in_seconds=prompt_length_in_seconds))sample_length_in_seconds = 30 # サンプルの長さ(秒)
hps.sample_length = (int(sample_length_in_seconds*hps.sr)//top_prior.raw_to_tokens)*top_prior.raw_to_tokens
assert hps.sample_length >= top_prior.n_ctx*top_prior.raw_to_tokens, f'Please choose a larger sampling rate'metas = [dict(artist = "アーティスト名", # アーティスト名を入力してください
genre = "ジャンル", # ジャンルを入力してください
total_length = hps.sample_length,
offset = 0,
lyrics = """We're no strangers to love
You know the rules and so do I
A full commitment's what I'm thinking of
You wouldn't get this from any other guy
I just wanna tell you how I'm feeling
Gotta make you understand
Never gonna give you up
Never gonna let you down
Never gonna run around and desert you
Never gonna make you cry
Never gonna say goodbye
Never gonna tell a lie and hurt you
We've known each other for so long
Your heart's been aching, but
You're too shy to say it
Inside, we both know what's been going on
We know the game and we're gonna play it
And if you ask me how I'm feeling
Don't tell me you're too blind to see
Never gonna give you up
Never gonna let you down
Never gonna run around and desert you
Never gonna make you cry
Never gonna say goodbye
Never gonna tell a lie and hurt you
Never gonna give you up
Never gonna let you down
Never gonna run around and desert you
Never gonna make you cry
Never gonna say goodbye
Never gonna tell a lie and hurt you
(Ooh, give you up)
(Ooh, give you up)
Never gonna give, never gonna give
(Give you up)
Never gonna give, never gonna give
(Give you up)
We've known each other for so long
Your heart's been aching, but
You're too shy to say it
Inside, we both know what's been going on
We know the game and we're gonna play it
I just wanna tell you how I'm feeling
Gotta make you understand
Never gonna give you up
Never gonna let you down
Never gonna run around and desert you
Never gonna make you cry
Never gonna say goodbye
Never gonna tell a lie and hurt you
Never gonna give you up
Never gonna let you down
Never gonna run around and desert you
Never gonna make you cry
Never gonna say goodbye
Never gonna tell a lie and hurt you
Never gonna give you up
Never gonna let you down
Never gonna run around and desert you
Never gonna make you cry
Never gonna say goodbye
Never gonna tell a lie and hurt you
""",
),
] * hps.n_samples
labels = [None, None, top_prior.labeller.get_batch_labels(metas, 'cuda')]アーティスト名とジャンルは下記サイトに一覧があります。
sampling_temperature = .98
lower_batch_size = 16
max_batch_size = 3 if model in ('5b', '5b_lyrics') else 16
lower_level_chunk_size = 32
chunk_size = 16 if model in ('5b', '5b_lyrics') else 32
sampling_kwargs = [dict(temp=.99, fp16=True, max_batch_size=lower_batch_size,
chunk_size=lower_level_chunk_size),
dict(temp=0.99, fp16=True, max_batch_size=lower_batch_size,
chunk_size=lower_level_chunk_size),
dict(temp=sampling_temperature, fp16=True,
max_batch_size=max_batch_size, chunk_size=chunk_size)]if sample_hps.mode == 'ancestral':
zs = [t.zeros(hps.n_samples,0,dtype=t.long, device='cuda') for _ in range(len(priors))]
zs = _sample(zs, labels, sampling_kwargs, [None, None, top_prior], [2], hps)
elif sample_hps.mode == 'upsample':
assert sample_hps.codes_file is not None
data = t.load(sample_hps.codes_file, map_location='cpu')
zs = [z.cuda() for z in data['zs']]
assert zs[-1].shape[0] == hps.n_samples, f"Expected bs = {hps.n_samples}, got {zs[-1].shape[0]}"
del data
print('Falling through to the upsample step later in the notebook.')
elif sample_hps.mode == 'primed':
assert sample_hps.audio_file is not None
audio_files = sample_hps.audio_file.split(',')
duration = (int(sample_hps.prompt_length_in_seconds*hps.sr)//top_prior.raw_to_tokens)*top_prior.raw_to_tokens
x = load_prompts(audio_files, duration, hps)
zs = top_prior.encode(x, start_level=0, end_level=len(priors), bs_chunks=x.shape[0])
zs = _sample(zs, labels, sampling_kwargs, [None, None, top_prior], [2], hps)
else:
raise ValueError(f'Unknown sample mode {sample_hps.mode}.')↑この処理には少し時間がかかります。(10~20分)
Audio(f'{hps.name}/level_2/item_0.wav')if False:
del top_prior
empty_cache()
top_prior=None
upsamplers = [make_prior(setup_hparams(prior, dict()), vqvae, 'cpu') for prior in priors[:-1]]
labels[:2] = [prior.labeller.get_batch_labels(metas, 'cuda') for prior in upsamplers]zs = upsample(zs, labels, sampling_kwargs, [*upsamplers, top_prior], hps)↑この処理にはかなり時間がかかります。(数時間)
この間はスリープ状態などで放っておくことをオススメします。
これでコマンド実行が完了しました!お疲れ様でした!
参考サイト
今回Jukebox AIを使用するにあたって、下記記事を参考にさせていただきました!

最後に
実際に作成したものです↓

私も完全に理解できたわけではなく、まだ試行錯誤している段階なのでとりあえずどんどん作ってみています!
みなさんもぜひチャレンジしてみてください。


コメント